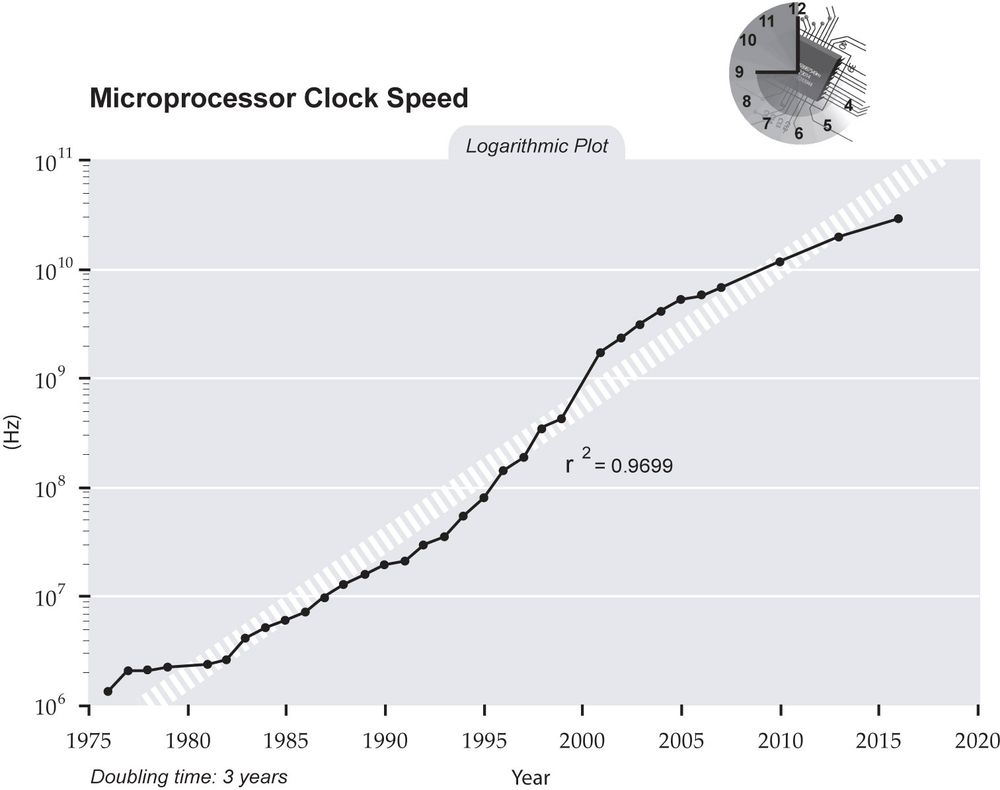
Clock speed is the most prominent specification given for CPUs, measured in cycles per second (hertz). Early CPUs had clock speeds in the thousands of hertz (kilohertz, or kHz) range, then they moved into the millions of hertz (megahertz, or MHz), and now they are in the billions of hertz (gigahertz, or GHz). This is used mostly for marketing purposes, as it's a simple figure to comprehend and correlates well with performance. But of course it's not that simple. The performance correlation only holds true when talking about the exact same model of CPU. When you start to involve different CPU architectures, or even different models of CPUs within the same architecture, this comparison becomes meaningless. For example, a 3Ghz Pentium D is much slower than a 3Ghz Core 2 Duo.
This is because clock speed is not actually a measure of performance in itself. The clock simply synchronises the different components within the CPU so that everything operates in proper order. The higher the clock speed, the more quickly these components operate. But this is far from the only thing that determines the CPU's performance. The design of the components themselves is a much more important matter. CPUs perform operations called 'instructions' on data to get results; some operations take multiple cycles to perform, others can be performed multiple times in a single cycle. Exactly how fast it can do these varies between CPU types, and that's why two CPUs can have the same clock speed, but vastly different performance. In the example above with the Pentium and Core, the Core is faster because it does more operations (more work) per clock cycle than the Pentium does.
When you put the clock speed together with the operations per cycle, and also consider the 'bit size' or data word length, you get a fairly decent estimate of performance. Measuring performance based on clock speed alone is usually referred to as the "megahertz myth," generally by companies competing with Intel, as Intel historically often approached the task of performance increase from the clock speed angle. For an early example, even in the very first stages of Computer Wars Intel's 8080 CPU and its Zilog's descendant, Z80, (clocked in the 2-4 MHz range) offered roughly the similar real speed as their main competitor, the MOS Technology 6502, clocked as much as twice slower (1-2 MHz).
Also, a processor cannot just move instantly from one clock cycle to the next. There is a lag between them, called latency. This is an issue with processors, but even more with RAM, which also has a clock speed. Latency means that there is a pause, when a component does nothing. It's the digital equivalent of inertia, and gets worse with poor hardware synchronization, because data has to sit and wait for components to open up for it. It's usually a microscopic fraction of a second, but with dynamic programs like video game graphics, latency cannot be ignored. High latency parts are either best left out of the system, or reserved for processing that doesn't involve graphics (physics, AI, and others).
Another issue with clock speed is in parallel operations. As an example, hard drives traditionally transferred data in parallel (16-bits at once). Later, when performance improved, two problems started to come to play. The first was most obvious, the highest performance drives, SCSI drives, had up to 68 pins with huge connectors and thick cables, both because the brute force approach of trying to transfer more bits in one clock tick simply required more pins, and because to lower the noise in the transmission lines every signal line had to be paired with the grounded one acting as its shield, making the cables physically very unwieldy.
The second is a problem in which the margin of error that bits could arrive in shrinks with clock speed. One of the reasons for the component latency is that due to propagation delays not all the bits arrive at once. So during a clock cycle there is usually the "sampling" period where the other side checks to see if a bit arrived, and "deskews" them so they all propagate to the next point together, and this period cannot be arbitrarily shortened because it depends on the physical design of the transmission line. This isn't really a problem in mostly internal connections when noise and other delays are kept to a minimum, especially at lower clock speeds, as the time window is wide enough for all bits to arrive and be properly rearranged.
But as lines grow longer and clock speeds increase, it becomes very hard to maintain data integrity, as the length of the clock cycle itself shrinks to the point that it may at some point become shorter than the physically dictated sampling period, making it impossible to ensure correct bit order. That is the main reason why serial interfaces became so popular now: as bits arrive one-after-one, there is no sampling and deskewing period, and the arriving bits could be simply stored in some buffer right away, allowing for the very high clock rates (or something equivalent in the asynchronous designs).
And if we need even higher transfer rates we may simply add some more serial lines, acting in parallel. Thus instead of having one transceiver, you can have multiple transceivers using the same mount of wires that can scale up or down as needed. This is the approach taken by the most popular PC expansion bus at this time, PCI-Express, which allows the expansion card to communicate with the motherboard through variable number of serial lines, called "lanes" in their parlance. Lower bandwidth cards, such as modems, TV tuners and such, use one or two lanes, while the GPUs, being the main bandwidth hogs, get 16 lanes all for themselves.
But lets throw a new wrinkle into the mix: multicore CPUs, where you have multiple "computers" inside the CPU. Now, that seems to mean that a dual-core CPU has twice as much computer as a single-core, or a quad-core is twice as fast as a dual core or four times as fast as a single core. It doesn't work that way.
First, the software has to be able to split the task into parts that can be performed in parallel. Many things can be divided that way, which is why multicore can improve games, but some things can't, e.g. printing payroll checks requires you do each check one at a time. There is an example of the difference between tasks that can be parallelized and those that can't. If you need to move out of a house, more people can carry more boxes and furniture, but you can't produce a baby in one month by getting nine women to perform the task.
Second, there is overhead in coordinating different parts of an application to use multicore processors efficiently, and because the "advertised" speed for a multicore CPU isn't necessarily the same speed as a single core CPU. You do get some speedup but it's in the nature of about 50%, so a dual core CPU gives you the equivalent of about 1.5 times a single core, a quad core is about twice, and a six-core is about three times as fast as a single core processor.
There's a new type of CPU called clockless CPUs. Where in a clocked CPU the CPU's components use the clock's signal to synchronize their activity, in a clockless CPU the components talk to each other to coordinate and synchronize their activity. A clockless CPU is capable of greater speeds than a clocked CPU, since the clock speed of a clocked CPU is limited by the worst case scenario (the slowest possible response time of the slowest component), but CPUs rarely deal with the worst case scenario, and most components will get their work done before the next clock tick comes; the time the components spend sitting there waiting for the next clock tick is time they could have spent actually doing something if they were in a clockless CPU. On the other hand, a clockless CPU is a lot trickier to design than a clocked one, and the massive amounts already existing software which helps humans design CPUs are geared towards designing clocked CPUs.
Therefore, clockless CPUs are mostly prototypes, none have been mass-produced for desktops or even cell phones yet. x86, ARM, and PPC (in that order) remain by far the most likely CPUs an end user will deal with.